4.5.3.1 - Crossvalidazione¶
Abbiamo visto come sia necessario suddividere il nostro dataset in almeno due insiemi, ovvero quelli di training e di validazione, allo scopo di assicurarci che il modello, addestrato sui dati di training, sia in grado di generalizzare le sue predizioni a casi che non ha mai visto durante l'addestramento.
Tuttavia nel tempo è emerso come questa procedura spesso non sia sufficiente: infatti, pur scegliendo i dati di training e testing in maniera completamente casuale, rimane una possibilità tutt'altro che remota che esistano dei particolari meccanismi di generazione dati specifici per quel determinato sottoinsieme di dati. In altre parole, permane il rischio che l'algoritmo vada in overfitting.
Per ovviare a questa evenienza, esiste una procedura specifica chiamata \(k\)-fold corss validation. In questa procedura, l'insieme di dati è suddiviso in \(k\) diverse porzioni, ognuna delle quali sarà usata come test set ad una specifica iterazione, con la restante parte usata come set di training. Dopo \(k\) iterazioni, i risultati saranno quindi mediati tra loro; questo farà in modo che il contributo di ogni singolo sottoinsieme di dati di training sia meno rilevante e, di conseguenza, il modlelo complessivo maggiormente robusto rispetto a fenomeni di overfitting. Graficamente, possiamo descrivere la \(k\)-fold cross validation con la figura 1, presa direttamente dalla documentazione di Scikit-Learn.
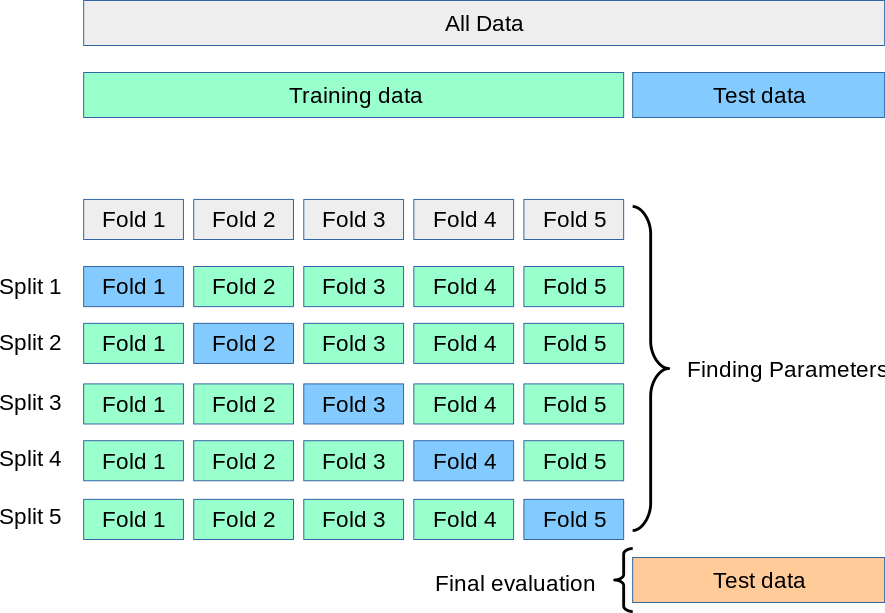
Strategie di cross validation
Esistono diverse strategie di cross-validation, le quali differiscono principalmente nel modo in cui sono assegnati i valori al test set.
Cross validation in Scikit-Learn¶
La funzione cross_val_score()¶
Il modo più semplice di effettuare la cross-validazione in Scikit-Learn è usare la funzione cross_val_score(), che accetta come parametri uno stimatore, i dati su cui si vuole che operi, e la metrica da analizzare. Ad esempio:
In questo caso, alla riga 4 calcoleremo l'adjusted rand index per un K-Means sui dati (X, y) con \(k\)=10.
Da notare che scores avrà al suo interno la media (scores.mean()) e la varianza (scores.std()) assunta dallo score durante le iterazioni di addestramento.
Da notare che cross_val_score() può anche essere usata con una Pipeline:
La funzione cross_validate()¶
Una funzione leggermente più complessa rispetto a cross_val_score() è cross_validate(), che differisce dalla prima per due aspetti:
- permette di valutare diverse metriche contemporaneamente;
- restituisce un dizionario che contiene, oltre agli score sul test set, anche i tempi impiegati per ottenere lo score e per addestrare l'algoritmo. Ad esempio:
La funzione cross_val_predict()¶
La funzione cross_val_predict() viene utilizzata per ottenere i valori predetti per ciascun elemento dell'input quando l'elemento stesso faceva parte del test set.
L'utilizzo della cross_val_predict() è consigliato in due casi, ovvero:
- quando vogliamo visualizzare le predizioni ottenute da diversi modelli;
- quando le predizioni di uno stimatore supervisionato sono usate per addestrare un altro stimatore in un modello ensemble (model blending).
Utilizzare la cross_val_predict()
A causa della sua natura, la cross_val_predict() può essere usata soltanto con strategie di cross validazione che assegnano tutti gli elementi del dataset ad un sottoinsieme di test esattamente una volta.